Here at MassMutual’s Data Science group we take on a lot of thorny insurance problems that can affect a lot of people. But it’s not always actuarial formulas and morbidity data sets. Our Big Data mindset often turns to other interests.
Like beer. Sure, it doesn’t seem all that serious. But helping people can involve a range of challenges…including helping people avoid skunky beer.
In 2009 there were 1,596 operating craft breweries in the United States. As of 2016, this number grew to 5,234 – a remarkable increase of over 225 percent in only 7 years! This growth has led to a marvelous variety of options for the beer lover, with new flavors and styles seeming to appear daily. As a beer lover, this bounty provides for near endless gustatory adventure.
However, there is one recent trend that I find truly alarming – the spread of India Pale Ales (IPAs)! These ales are best known for their strong hops flavor, which I personally cannot stand.
Fortunately, data science provides a way to avoid these nasty brews. I downloaded the Craft Beer Dataset cultivated by Jean-Nicholas Hould. This dataset covers 2,410 craft beers from 510 U.S. breweries and provides the Alcohol By Volume (ABV), International Bittering Units (IBU), name, style, and ounces. I approached the problem by asking a simple question: Can I predict if a beer is an IPA from only its ABV and IBU?
To start, we must identify which beers in the dataset are IPAs. There are 99 distinct styles in this set, from “Abbey Single AleBeer” to “Witbier.” We also see many different types of IPAs, including “English India Pale Ale”, “American White IPA”, and “American IPA.” To simplify our study, we will group all IPA’s together. We also find that 1,005 of the 2,410 beers lack either the ABV, the IBU, or the style. We exclude this data.
We can similarly group together other styles like Blonde Ales, Stouts, and, my personal favorite, Porters. The plot below shows the ABV and IBU for the different styles of beer. We can see that the IPAs tend to be more alcoholic and bitter.
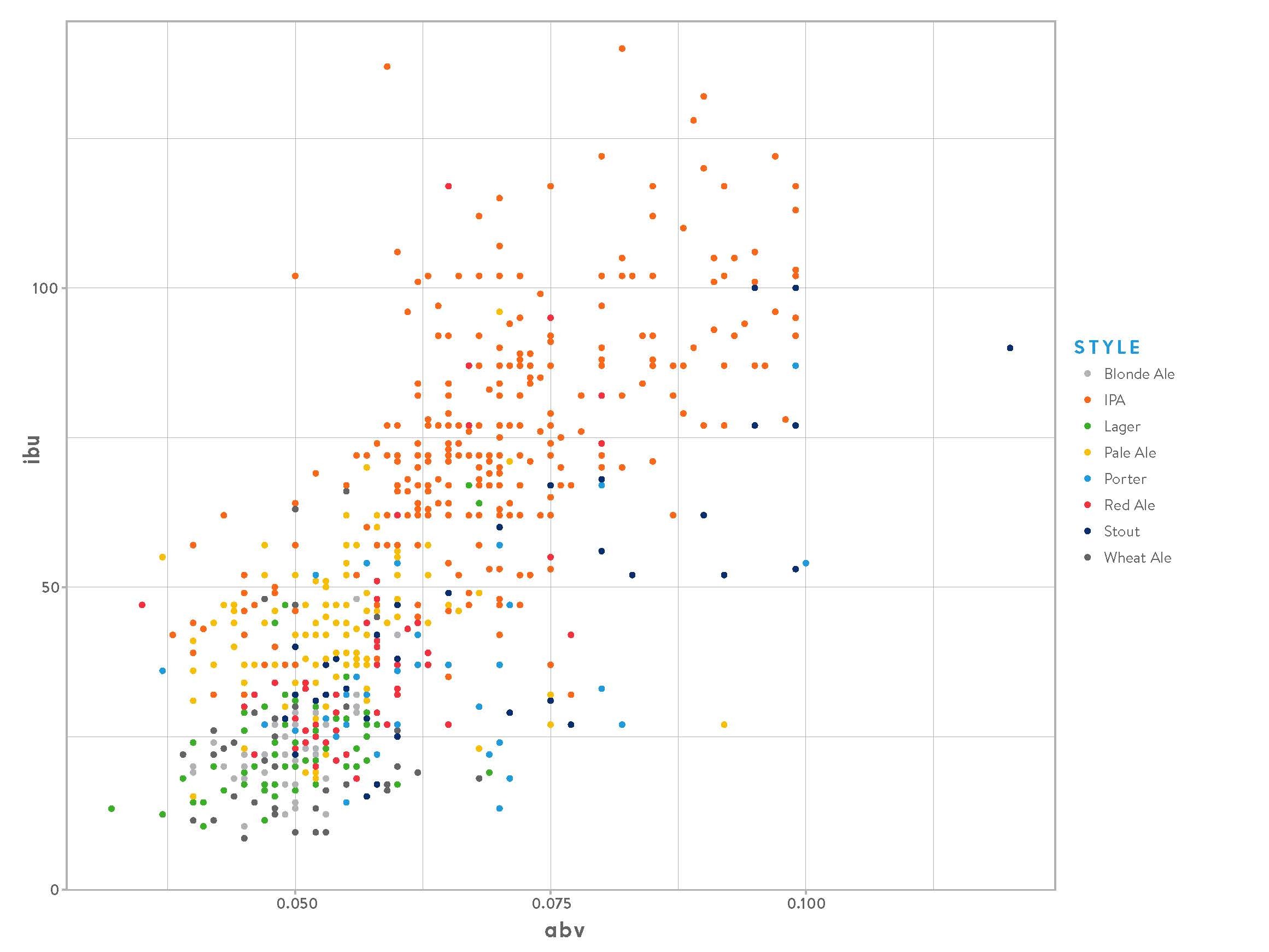
But is this enough to identify them?
I will make predictions by using a classification tree, also known as a decision tree. This tree is constructed by splitting the set of beers apart repeatedly in order to end up with groups that are all of the same type.
We begin with all the beers in a single group. In this grouping there is a 28 percent chance that a beer is an IPA. However, if we split the population into two groups – those with IBU less than 59 and those with IBU greater than or equal to 59 – we achieve much better accuracy.
We want to use the data about IBU and ABV to partition the data into two groups such that each group is of similar size but have different percentages of IPAs. By examining the percentage of IPAs and the size of the two remaining groups when splitting across different values of IBU and ABV, we find that splitting on an IBU value of 59 gives us groups of similar size, and with a value of 0.076 IPAs in one group, and 0.77 IPAs in the other group.
So beers with IBU less 59 are IPAs only 7.6 percent of the time, while those with IBU greater than or equal to 59 are IPAs 77 percent of the time. Further splits can be made to both groups, shown in the tree below.
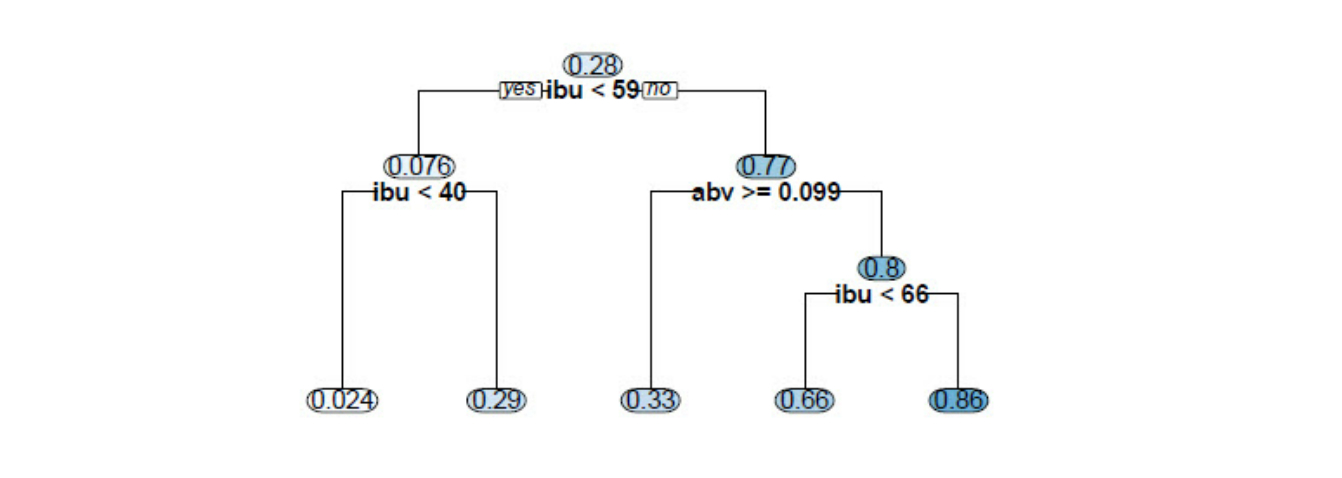
Ultimately, to avoid IPAs, I should stay away from anything with an IBU above 59, especially when the ABV is greater than 0.099. Beers with an IBU below 40 are particularly safe, with only 2.4% classified as IPAs.
See? The same data science methods we use here at MassMutual to tackle some of the industry’s tougher actuarial challenges can be brought to bear on more everyday issues as well…like avoiding hoppy beer.
Cheers!
____________________________
More from MassMutual...
MassMutual's data science/grad school program
Data science at MassMutual: A grad's view
MassMutual's Green Bay Packers connection
_____________________________________
The information provided is not written or intended as specific tax or legal advice. MassMutual, its employees and representatives are not authorized to give tax or legal advice. You are encouraged to seek advice from your own tax or legal counsel. Opinions expressed by those interviewed are their own, and do not necessarily represent the views of Massachusetts Mutual Life Insurance Company.